Six practical steps to architect and implement an end-to-end MuleSoft IDP solution
Enterprises today receive thousands of documents daily—purchase orders, invoices, KYC forms, claims, contracts—arriving through emails, portals, scanners, and APIs. Traditional OCR-based automation struggles with scale, accuracy, and change.
MuleSoft Intelligent Document Processing (IDP) combines AI-driven extraction with API-led connectivity, enabling organizations to move from document handling to business outcomes.
This blog walks through the six practical steps to architect and implement an end-to-end MuleSoft IDP solution.
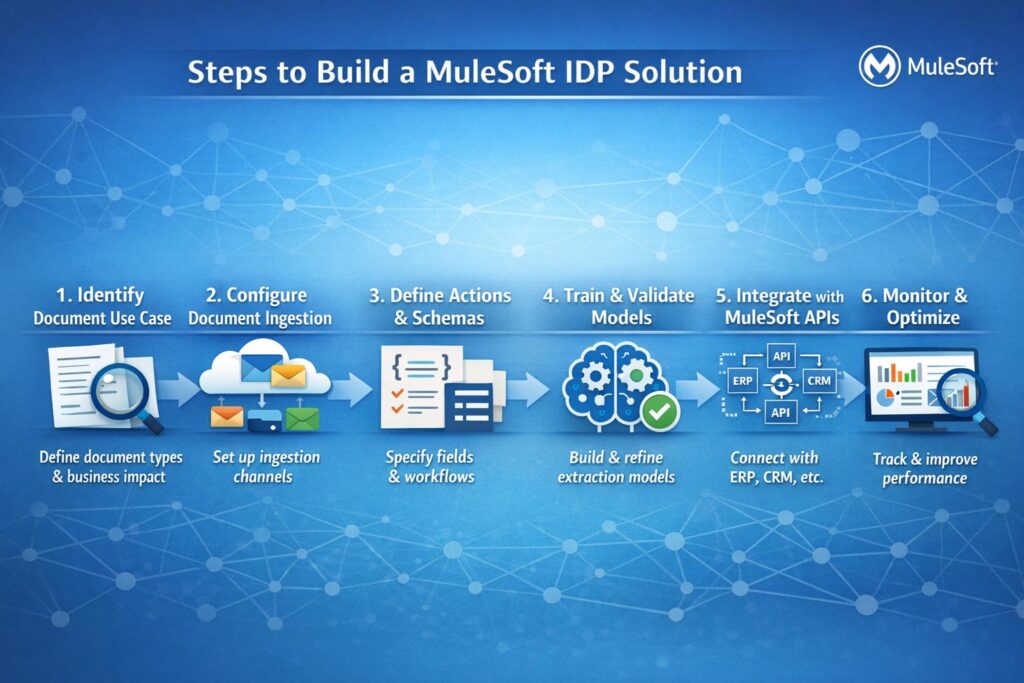
- Identify document use case
- Configure document ingestion
- Define document actions and schemas
- Train and validate extraction models
- Integrate with MuleSoft APIs
- Monitor and optimize
Let’s deep dive into each of them now
1. Identify the Document Use Case
Every successful IDP initiative starts with clear problem definition, not technology selection.
What to identify first
- Document types
Invoices, POs, delivery notes, Timesheets, KYC forms, insurance claims, contracts - Structure level
- Structured (fixed layouts)
- Semi-structured (varying templates)
- Unstructured (free-form text)
- Business impact
- Manual effort reduction
- Faster turnaround time
- Error reduction
- Compliance and audit readiness
MuleSoft best practice
Start with high-volume, semi-structured documents (e.g., vendor invoices or purchase orders). These provide:
- Faster ROI
- Easier model training
- Clear success metrics
2. Configure Document Ingestion
Once the use case is defined, the next step is capturing documents reliably.
Common ingestion channels
- Email (invoices@company.com)
- SFTP / file drops
- Web portals
- REST APIs
- Scanner uploads
- Cloud storage (S3, SharePoint)
MuleSoft ingestion approach
- Experience APIs receive documents
- Metadata is extracted (source, timestamp, sender)
- Documents are securely routed to IDP
- Large files handled asynchronously
Key considerations
- Virus scanning and validation
- Duplicate detection
- Secure storage and encryption
- Correlation IDs for traceability
3. Define Document Actions and Schemas
IDP success depends on what data you expect, not just what the document contains.
Define document actions
- Extract
- Validate
- Classify
- Route
- Escalate for human review
Define schemas clearly
For an invoice:
- Invoice Number
- Invoice Date
- Vendor Name
- Line Items
- Tax Amount
- Total Amount
- Currency
4. Train and Validate Extraction Models
AI models improve with feedback—and MuleSoft IDP is designed for continuous learning.
Training approach
- Upload sample documents
- Label key fields
- Train extraction models
- Validate accuracy per field
Human-in-the-loop (HITL)
- Low-confidence fields routed for review
- Human corrections captured
- Feedback improves future predictions
Best practices
- Set confidence thresholds per field
- Start with fewer fields, expand gradually
- Track accuracy trends over time
5. Integrate with MuleSoft APIs
This is where MuleSoft truly differentiates IDP from standalone tools.
API-led integration
- Experience APIs
Trigger IDP, provide status, expose dashboards - Process APIs
Orchestrate validation, enrichment, approvals - System APIs
Push data to ERP, CRM, Core Banking, SAP, Salesforce
Event-driven patterns
- Publish events when extraction completes
- Trigger downstream workflows asynchronously
- Enable real-time and batch coexistence
6. Monitor and Optimize
IDP is not a one-time deployment—it is a living system.
What to monitor
- Extraction accuracy per field
- Manual review rates
- Processing latency
- Cost per document
- Failure patterns
Optimization levers
- Adjust confidence thresholds
- Improve prompts and models
- Add validation rules
- Introduce RPA for legacy UI gaps
- Scale horizontally with APIs
Final Thoughts: From Documents to Decisions
MuleSoft IDP is not just about reading documents—it’s about connecting intelligence to action.
When architected correctly, IDP becomes:
- A reusable enterprise capability
- A data quality accelerator
- A foundation for AI-driven decisioning
By following these six steps, organizations can move from manual document chaos to API-driven, intelligent operations—at scale.
Tips for Architects
- Avoid boiling the ocean. Solve one document type end-to-end before scaling.
- Treat ingestion as an API product, not a file transfer.
- Be stricter with amounts, dates, and identifiers—these drive financial risk.
- Accuracy is not binary—design for graceful degradation, not perfection.
- IDP should emit events, not create point-to-point dependencies.
- Observability turns IDP from automation into a strategic capability.
